传统和遗传关联:肥胖与 1463 种蛋白质在相对瘦的中国成年人中的关联
该研究旨在探究肥胖与1463种蛋白质在相对瘦的中国成年人中的传统和遗传关联,以下是具体内容总结: ### 一、研究方法与对象 - 研究对象为中国嘉道理生物银行(CKB)中的3977名中国成年人,平均基线BMI为23.9(3.3)kg/m²,仅6%为肥胖(BMI≥30 kg/m²)。同时在英国生物银行(UKB)的约5万名参与者中进行了复制分析。 - 采用测量的BMI和基因工具化的BMI,通过线性回归等方法分析肥胖与1463种血浆蛋白质水平的关联,运用双向孟德尔随机化(MR)分析评估某些蛋白质是否影响肥胖,并进行富集分析等以阐明潜在机制。 ### 二、主要研究结果 1. BMI与蛋白质的关联: - 在观察性分析中,BMI与1096种蛋白质显著相关(FDR<0.05),其中826种呈正相关,270种呈负相关。经Bonferroni校正后,仍有798种蛋白质与BMI显著相关。 - 遗传分析中,基因工具化的BMI与307种蛋白质显著相关(FDR<0.05),其中270种呈正相关,37种呈负相关。这些关联在很大程度上呈线性,且在肥胖到蛋白质的方向上,在UKB的欧洲人中复制率超过90%。 - 表现出最强正遗传关联的蛋白质包括FABP4、LEP、IL1RN等,最强负遗传关联的蛋白质包括PON3、NCAN、LEPR等。 2. 富集分析: - 对排名前50多位的BMI相关蛋白质进行富集分析,发现它们参与动脉粥样硬化、脂质代谢、肿瘤进展和炎症等过程。 3. 双向MR分析: - 利用CKB全基因组关联研究(GWAS)中识别的顺式蛋白质数量性状位点(cis-pQTLs)进行双向MR分析,发现8种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15、PRDX6)显著影响BMI水平,其中NUDT5还表现出双向关联。 ### 三、研究结论 - 该研究在相对瘦的中国成年人中发现了肥胖可能增加疾病风险的新途径,以及治疗肥胖和肥胖相关疾病的新潜在靶点。研究结果表明,肥胖与大量蛋白质存在关联,且部分关联具有因果性,这些蛋白质涉及多个生物学过程,为理解肥胖相关疾病的机制提供了新见解。
数据可用性
中国嘉道理生物样本库(CKB)是一个全球性资源,用于研究生活方式、环境、血液生化和遗传因素作为常见疾病的决定因素。CKB研究小组致力于向中国、英国及全球的科学界提供队列数据,以增进对疾病病因、预防和治疗的认识。 关于目前向开放获取用户提供的数据内容以及申请方式的详细信息,请访问:http://www.ckbiobank.org/site/Data+Access。 研究人员需提交研究方案,以确保所有分析均由真正的研究人员开展。有意获取本文所依据的额外信息或数据的研究人员,请联系ckbaccess@ndph.ox.ac.uk。对于任何目前未开放获取的数据,研究人员可能需要与研究小组建立正式的合作关系。
代码可用性:本报告中的所有统计分析均使用了自定义代码。
摘要
肥胖与多种疾病和特征相关,但人们对这些关联的因果相关性及潜在机制知之甚少。大规模蛋白质组学分析,尤其是与遗传数据相结合时,能够阐明将肥胖与疾病结局联系起来的机制。我们利用测量的体重指数(BMI)和基因工具化的BMI,在3977名中国成年人中研究了肥胖与1463种血浆蛋白质水平的关联。我们进一步使用两样本双向孟德尔随机化(MR)分析来评估某些蛋白质是否会影响肥胖,同时结合其他(如富集)分析来阐明观察到的关联背后可能的机制。总体而言,基线BMI的平均值(标准差)为23.9(3.3)kg/m²,仅有6%的人属于肥胖(即BMI≥30 kg/m²)。在错误发现率(FDR)<0.05的水平上,测量的BMI和基因工具化的BMI分别与1096种(正相关/负相关:826/270)和307种(正相关/负相关:270/37)蛋白质的水平显著相关。其中,FABP4、LEP、IL1RN、LSP1、GOLM2、TNFRSF6B和ADAMTS15表现出最强的正遗传关联,而PON3、NCAN、LEPR、IGFBP2和MOG表现出最强的负遗传关联。这些关联在很大程度上呈线性,方向为肥胖到蛋白质,并且在英国生物银行(UKB)的欧洲人中(平均BMI为27.4 kg/m²)得到了超过90%的重复验证。对与BMI相关的排名前50多种蛋白质的富集分析表明,它们参与了动脉粥样硬化、脂质代谢、肿瘤进展和炎症等过程。利用中国嘉道理生物银行(CKB)==全基因组关联研究(GWAS)==中识别的顺式蛋白质数量性状位点(cis-pQTLs)进行的两样本双向MR分析发现,8种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15、PRDX6)显著影响BMI水平,其中NUDT5还表现出双向关联。在相对瘦的中国成年人中的研究结果,发现了肥胖可能增加疾病风险的新途径,以及治疗肥胖和肥胖相关疾病的新潜在靶点。
介绍
全球范围内,肥胖影响着约7亿成年人,包括中国在内的大多数国家,肥胖患病率仍在持续稳步上升[1]。肥胖(或更广泛地说, adiposity)对代谢特征(如脂质、血糖和血压)、心血管疾病、2型糖尿病以及某些癌症的影响已得到充分证实[2-7]。然而,对于 adiposity 在许多其他疾病中的病因学作用,以及将 adiposity 与个体疾病联系起来的机制,仍存在很大的不确定性。
脂肪组织除了作为能量储存的场所外,无论是位于皮下脂肪、肌周脂肪、腹腔内脂肪、内脏之间,甚至是内脏内部(如肝脏中),还具有内分泌器官的功能[8]。因此,脂肪组织会产生激素(如瘦素、雌激素和抵抗素)、炎症生物标志物、脂肪酸和脂肪细胞因子[8],这些物质可作用于多个身体系统,引发多种疾病,其影响范围超出了已确定的代谢途径。此外,很可能还有多种与肥胖相关的新型生物标志物(如循环蛋白质和小分子)尚未被发现。
大多数可药用靶点是蛋白质,包括酶、蛋白激酶和转运蛋白[9]。随着高通量蛋白质组学检测技术的出现,对人类大量循环蛋白质进行系统表征直到最近才成为可能[9-11]。对蛋白质血浆水平与肥胖相关特征的观察性和遗传性关联分析表明,新型蛋白质参与了疾病病因学以及将肥胖(和其他风险因素)与多种疾病联系起来的分子途径[12-17]。然而,现有的蛋白质组学证据存在一定局限性:相关研究多采用靶向心脏代谢或炎症检测 panel,涉及的蛋白质数量相对较少[12-14];或研究对象局限于西方人群,而这些人群中大多数人超重或肥胖[13-17];或使用自我报告的肥胖测量数据[15];且往往缺乏伴随的遗传分析来评估这些关联的因果相关性和方向(即是肥胖到蛋白质的方向,还是反之)[14]。 对中国成年人中肥胖与蛋白质生物标志物关联的全面评估应具有特别的信息价值,因为中国人群的平均肥胖水平(如平均 BMI 为 22-24 kg/m²)、体型和遗传结构与西方人群存在显著差异。
我们对从中国嘉道理生物银行(CKB)中选取的3977名中国成年人进行了肥胖与1463种蛋白质的观察性和遗传性分析。本研究的主要目的是识别与体重指数(BMI)显著相关的血浆蛋白质,并阐明观察到的关联的形式、强度和因果相关性。此外,我们还使用基因本体论(GO)富集分析来探究特定类别蛋白质是否受BMI影响,并通过双向孟德尔随机化(MR)分析来研究某些蛋白质是否也会因果性地影响BMI水平。
方法
Study population
中国嘉道理生物银行(CKB)的设计和方法细节已在先前的报告中阐述[18, 19]。简要来说,2004–2008年期间,研究从10个地理上多样化的地区(5个城市、5个农村)招募了512,869名年龄在30–79岁的参与者。在基线调查中,参与者完成了由调查员指导的基于笔记本电脑的问卷调查,内容涉及社会人口统计学和生活方式因素(如吸烟、饮酒和体育活动)、病史和用药情况(如他汀类药物);接受了身体测量(如血压、心率、身高、体重以及腰围和臀围);并提供了10毫升非空腹血液样本(记录了距上次进餐的时间)用于长期储存。该研究事先获得了国际、国家和地区的伦理批准,所有参与者均提供了书面知情同意书。
Anthropometric measurements
人体测量时,参与者需穿着轻便衣物但不穿鞋,测量结果通常精确到0.1厘米或0.1千克。体重使用身体成分分析仪(TANITA-TBF-300GS;百利达公司)测量,其中夏季需减去0.5千克衣物重量,春秋季减去1.0千克,冬季减去2.0–2.5千克。体重指数(BMI)的计算方法为体重(千克)除以身高(米)的平方(kg/m²)。
蛋白质组学检测
蛋白质组学检测在3977名中国嘉道理生物银行(CKB)参与者中进行,这些参与者既往无心血管疾病史,在样本收集时未使用降脂药物(如他汀类药物),但拥有全基因组基因分型数据。参与者是作为一项巢式病例队列研究的一部分被选取的,该研究包括1951例 incident 缺血性心脏病(IHD)病例和2026名随机选取的亚队列个体(补充图1)。
研究人员取出参与者储存的基线血浆样本,解冻后分装成多个 aliquots,其中一份(100微升)用干冰冷藏运往瑞典乌普萨拉的OLINK生物科学实验室,采用多重邻近延伸分析法进行蛋白质组学分析。为减少批间和批内变异,样本在不同平板间随机分布,并使用内部对照(延伸对照)和板间对照进行标准化,随后应用预先确定的校正因子进行转换。
OLINK检测的性能和验证细节已在其他文献中报道[10]。检测限(LOD)通过阴性对照样本(不含抗原的缓冲液)确定。若孵育对照与平板上所有样本的中值偏离超过预设值(±0.3),则该样本会被标记为存在质量控制警告(但检测限以下的值仍纳入分析)。预处理数据以任意的标准化蛋白表达(NPX)单位呈现,且处于log2尺度上。
本研究共分析了1472种蛋白质,其中3种(IL6、IL8和TNF)在所有四个独立检测组中均被重复检测到,最终得到1463种独特的蛋白质(补充表1)。部分蛋白质的分布存在偏态(补充图2),每个蛋白质在所有样本中的质量控制警告数量相对较少(例如,106种蛋白质的质量控制警告涉及所有样本的4.0%:补充表2),这些蛋白质均纳了主要分析。
Genotyping and genetic instruments for BMI
基因分型采用定制设计的800K-SNP芯片(Axiom [Affymetrix])对约10万名通过质量控制的中国嘉道理生物银行(CKB)参与者进行,所有变异的总检出率>99.97%,其中包括约7.6万名从整个队列中随机选取的基于人群的样本,本研究中的2026名亚队列个体便从中选出。
BMI遗传评分(BMI GS)是利用CKB和英国生物银行(UKB)中性别合并的跨 ancestry全基因组关联研究(GWAS)中达到全基因组显著水平的位点得出的:分别对816个 minor allele 频率≥0.01且与BMI相关的变异的剂量,根据其在UKB中的效应量进行加权。该BMI遗传评分(F统计量:152)是一个强工具变量(解释了3.7%的方差),且与吸烟或饮酒等混杂因素无关(补充表3)。
双向孟德尔随机化(MR)分析的遗传工具是每种蛋白质的全基因组关联研究(GWAS)中的顺式蛋白质数量性状位点(cis-pQTLs)。
Statistical analysis
按体重指数(BMI)五分位数计算基线特征的患病率或平均值,并按病例和亚队列的年龄(5年组)、性别和研究地区结构进行标准化。
血浆蛋白质水平经过标准化处理(即每种蛋白质的数值除以其标准差),并作为连续变量进行分析。
在观察性分析中,采用线性回归评估BMI与蛋白质生物标志物之间的关联,调整因素包括年龄、年龄平方、性别、研究地区、空腹时间、环境温度、平板编号以及病例-亚队列确定方式。对于每种生物标志物,估算与 adiposity 水平每升高1个标准差相关的调整后差异及95%置信区间。
在遗传(即孟德尔随机化)分析中,我们采用两阶段最小二乘估计法探究基因工具化体重指数(BMI)与蛋白质之间的关联。
首先,通过线性回归分析BMI遗传评分(BMI GS)与BMI测量值之间的关联,调整因素包括年龄、年龄平方、性别、研究地区、空腹时间、环境温度、病例-亚队列确定方式以及前12个全国性主成分。
其次,采用线性回归分析由此得到的预测BMI值与蛋白质组学测量值之间的关联,调整因素与上述相同(包括平板编号),但不包括主成分。我们计算了BMI每升高3.6 kg/m²(相当于观察性分析中1个标准差的升高)时,基因工具化的蛋白质水平关联,以便与观察性分析结果进行比较。为验证主要研究结果,我们还在英国生物银行(UKB)中进行了单独的观察性和遗传性分析,涉及约5万名参与者的1463种OLINK Explore蛋白质[16]。
为探究观察性分析中关联的形式,研究通过多元线性回归计算了每个BMI五分位数内个体蛋白质的校正均值,然后将其与每个五分位数内的平均BMI进行绘图。
同样,在遗传分析中,研究通过基于遗传评分校正后BMI(GS-free BMI)的五分位数进行分层,开展了非线性孟德尔随机化(MR)分析。遗传评分校正后BMI的计算方式为:以总体人群平均BMI(23.9 kg/m²)为中心,取BMI对遗传评分(GS)回归的残差。
随后,研究采用比率法计算每个分层的因果估计值:以BMI与遗传评分关联的总体估计值作为分母,以每个遗传评分校正后BMI五分位数内遗传评分与每种蛋白质关联的估计值作为分子。
研究使用分段线性法估算每个遗传评分校正后BMI分层的均值,将因果估计值作为每个分层中直线的斜率。每个线段从前一个线段的终点开始,截距设定为人群平均BMI。通过对每个遗传评分校正后BMI分层样本中遗传评分与蛋白质生物标志物的关联进行 bootstrap 抽样,估算出置信区间(CI),并针对每种蛋白质在遗传评分校正后BMI各分层中的因果估计值计算趋势检验和二次检验的χ²值。
在敏感性分析中,我们(i)仅将分析限定于亚队列参与者;(ii)排除了带有质量控制警告的值;(iii)对额外的协变量(如教育程度、吸烟、饮酒和体育活动)进行了调整;(iv)排除了有既往疾病的个体。我们还进行了按性别分层的分析,以检验男性和女性之间结果的一致性。
对于在遗传分析中(肥胖到蛋白质的方向)达到Bonferroni校正阈值的蛋白质,我们使用clusterProfiler(v.4.2.2)软件[23]进行了基因本体论(GO)和京都基因与基因组百科全书(KEGG)富集分析,通过超几何检验来确定哪些生物学功能或过程显著富集。
在中国嘉道理生物银行(CKB)参与者的全基因组关联研究(GWAS)分析中,采用COJO方法确定蛋白质数量性状位点(pQTLs),统计学显著性阈值设为P<5×10⁻⁸[24]。此外,对于所有具有可用顺式蛋白质数量性状位点(cis-pQTLs,即编码基因区域±500kb范围内)的蛋白质,我们进行了两样本双向孟德尔随机化(MR)分析,具体包括:(i)使用从CKB的GWAS中获得的顺式蛋白质数量性状位点,分别在日本生物银行(BBJ,n=173,430)中查询[25];(ii)使用从英国生物银行(UKB)的GWAS中获得的顺式蛋白质数量性状位点,在包含英国生物银行参与者(n≈700,000)[26]或不包含英国生物银行参与者(n≈210,000)[27]的遗传人类学特征研究(GIANT)中查询。
两种分析均采用两阶段最小二乘估计法和 Wald 比率法[28,29]。 对于在两样本孟德尔随机化分析中显示出显著关联的蛋白质,我们使用孟德尔随机化Steiger过滤法检验每个提取的单核苷酸多态性(SNP)对蛋白质水平和体重指数(BMI)的因果方向[30]。
对于目标蛋白质,我们还使用coloc(v5.2.1)进行共定位分析,以探究它们是否与BMI共享相同的因果变异,并利用STRING数据库(v11.5)探究蛋白质间的相互作用。
我们筛选了基因型-组织表达(GTEx,v8)数据库[31],以检查这些因果蛋白质在肥胖中的组织特异性作用,并选取了参与能量代谢或食物摄入内分泌调控的组织。我们进一步检索了表型扫描器(PhenoScanner,v2)和全基因组关联研究目录(GWAS Catalog,v1.0.2),以寻找来自中国嘉道理生物银行和英国生物银行的顺式蛋白质数量性状位点与一系列表型的关联,采用的P值阈值为5×10⁻⁸。
所有统计分析均使用R 4.1.2版本进行。显著性阈值采用Benjamini–Hochberg错误发现率(FDR)或更严格的Bonferroni校正阈值(0.05/1463)来校正多重检验。
结果
在接受研究的3977名参与者中,基线时的平均年龄(标准差)为57.3(11.6)岁,平均体重指数(BMI)为23.9(3.3)kg/m²,其中6%为肥胖人群(即BMI≥30 kg/m²)。BMI较高的参与者血压水平更高,更有可能是城市居民和女性,且吸烟的可能性更低(仅针对男性)(表1)。这些关联在缺血性心脏病(IHD)病例和亚队列参与者中大致相似,不过IHD病例的平均血压水平高于亚队列参与者(补充表4)。
体重指数(BMI)与蛋白质的观察性关联
总体而言,在错误发现率(FDR)<0.05 的水平上,体重指数(BMI)与 1096 种蛋白质的血浆水平显著相关,其中 826 种呈正相关,270 种呈负相关(图 1a 和补充图 3)。应用 Bonferroni 显著性阈值后,仍有 798 种蛋白质(625 种正相关,173 种负相关)与 BMI 显著相关。
在所有检测的 BMI 范围内,BMI 与几乎所有个体蛋白质的关联均呈线性(补充图 4),尽管关联强度存在差异 —— 每标准差 BMI 升高对应的效应量,正相关为 0.01 至 0.55,负相关为 - 0.45 至 - 0.01(图 2a)🔶2-59🔶。
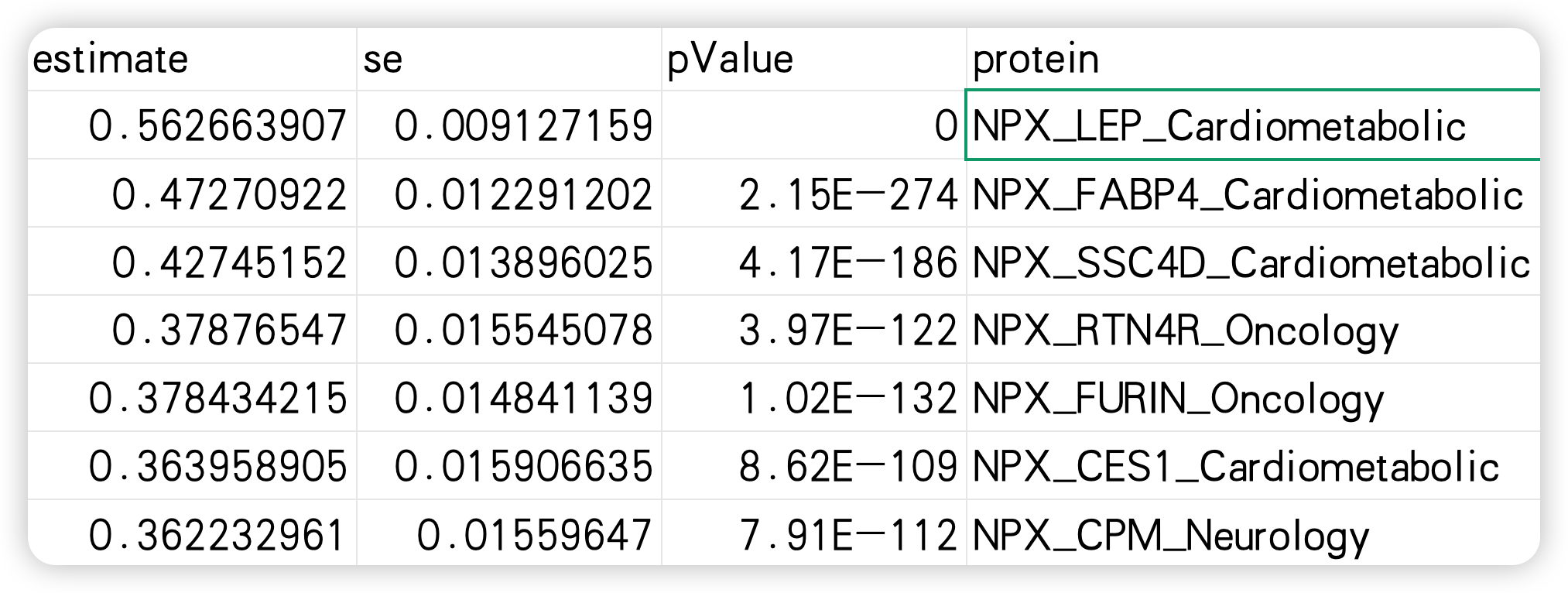
与 BMI 呈最强正相关的蛋白质为瘦素(leptin)、脂肪细胞型脂肪酸结合蛋白(FABP4)、SSC4D、钙粘蛋白相关家族成员 2(CDHR2)和弗林蛋白酶(FURIN);而呈最强负相关的蛋白质为胰岛素样生长因子结合蛋白 2(IGFBP2)、胰岛素样生长因子结合蛋白 1(IGFBP1)、血清对氧磷酶 / 内酯酶 3(PON3)、WFIKKN2 和瘦素受体(LEPR)。BMI 与所有个体蛋白质的相关结果详见补充表 5。
在仅针对亚队列参与者的敏感性分析中,体重指数(BMI)在错误发现率(FDR)<0.05 的水平上与 984 种蛋白质相关(补充图 5),其中超过 97% 与主要分析中的蛋白质重叠,且所有关联的方向均一致。此外,整体的或主要的面板特异性蛋白质与主要分析中的完全相同。同样,额外排除以下人群后,结果未发生实质性改变:(i)有糖尿病、肾病或癌症既往史的个体;(ii)在特定检测中出现质量控制(QC)警告的个体;或(iii)对其他协变量进行额外调整后(补充表 6)。
在对所有参与者进行的性别特异性分析中,男性中有 921 种蛋白质、女性中有 970 种蛋白质在错误发现率(FDR)<0.05 的水平上与体重指数(BMI)显著相关,两者的皮尔逊相关系数(r)为 0.87。男性和女性之间有 786 种蛋白质存在重叠关联,除 9 种蛋白质外,所有关联的方向均一致(补充图 6)。
体重指数(BMI)与蛋白质的遗传关联
在这 307 种蛋白质中,279 种(91%)在观察性分析中也显示出显著关联(图 2b),除 3 种蛋白质(CKMT1A_CKMT1B、MMP12 和 SLAMF7,在观察性分析中均呈负相关,而在遗传分析中呈正相关)外,其余所有蛋白质的关联方向均一致(242 种正相关,34 种负相关)。
图 2: 在中国嘉道理生物银行(CKB)的常规分析和遗传分析中,1 个标准差(SD)高的体重指数(BMI)与 1463 种蛋白质的关联,以及 CKB 和英国生物银行(UKB)之间遗传关联的比较。分析已调整年龄、年龄平方、性别、研究地区、空腹时间、环境温度、确定状态、检测板 ID 和前 12 个主成分(仅针对遗传分析)。
a 和 b 中的虚线表示多重检验校正后的统计显著性阈值,红点表示显著的正相关关联,蓝点表示显著的负相关关联,并标注了某些选定蛋白质的名称。c 和 d 中的黑色实心点是在 CKB 的常规分析和遗传分析中(左图)或在 CKB 和 UKB 中(右图)均与 BMI 显著相关的蛋白质,并标注了某些选定蛋白质的名称。
观察性分析与孟德尔随机化(MR)估计的 β 系数之间存在强相关性,BMI 的皮尔逊相关系数为 0.69(0.66–0.72),剔除所有不显著的蛋白质后,该系数升至 0.85(0.81–0.88)。
此外,在所有检测的 BMI 范围内,这些关联大致呈线性(趋势 P 值 < 0.05)(图 3)。
◂ 图 3 按 OLINK 检测组分类的体重指数(BMI)与 20 种选定蛋白质的遗传关联。采用非线性孟德尔随机化(MR)分析探究遗传关联的形式。在每个检测组中,纳入了与 BMI 关联最强的 5 种蛋白质(4 种正相关,1 种负相关)。采用分段线性法计算估计值(已调整年龄、年龄平方、性别、研究地区 [10 个组]、确定状态、检测板 ID 和 12 个全国性主成分)。每个线段从前一个线段结束处开始(黑线),截距设定为人群平均 BMI(红点)。阴影部分代表 95% 置信区间(CI)。y 轴长度约为相应蛋白质均值的 ±2 个标准差。
相反,在 1156 种与 BMI 无显著线性遗传关联的蛋白质中,91 种(7.9%)显示出与 BMI 存在二次关联的证据(补充图 7),但经过多重检验校正后,均无显著性。
每 1 个标准差(SD)更高的预测 BMI 所对应的遗传关联强度,正相关为 0.01 至 0.60,负相关为 - 0.55 至 - 0.01。与 BMI 呈最强正相关的蛋白质为 FABP4,其次为瘦素(leptin)、GOLM2、LSP1 和 ADAMTS15(图 2b 和补充图 8)。与 BMI 呈最强负相关的蛋白质为 PON3,其次为 NCAN、LEPR、B4GAT1 和 CHGB。所有个体蛋白质的孟德尔随机化(MR)结果详见补充表 7。
在仅针对亚队列参与者的敏感性分析中,显著关联的蛋白质数量较少(83 种)(补充图 9)。在这 83 种蛋白质中,80 种(96%)与主要结果中的蛋白质重叠,且所有关联的方向均一致(57 种正相关,23 种负相关)。此外,整体的主要蛋白质谱与主要分析中的完全相同。
在性别特异性分析中,男性和女性中分别有 59 种和 72 种蛋白质在错误发现率(FDR)<0.05 的水平上与基因衍生的体重指数(BMI)显著相关。其中有 18 种蛋白质存在重叠关联,且所有关联的方向均无差异(13 种正相关,5 种负相关),但男性中的效应量略大于女性(β 系数的皮尔逊相关系数 r=0.56 [0.52–0.59])(补充图 6)。
英国生物样本库中的复制分析
在对英国生物样本库(UKB)的49,736名参与者进行的复制分析中[16],我们发现,在传统的观察性分析中,有1379种(94%)蛋白质与体重指数(平均为27.4 kg/m²)在错误发现率(FDR)<0.05的水平上显著相关(图1)。在这1379种蛋白质中,有1064种(97%;1064/1096)在中国嘉道理生物样本库(CKB)中也与体重指数显著相关,重叠蛋白质效应量的皮尔逊相关系数为0.86(0.84–0.87)。在遗传分析中,有935种蛋白质与遗传衍生的体重指数显著相关(图1),其中大多数(96%;295/307;图2d)在CKB中被识别出的蛋白质得到了复制,重叠蛋白质效应量之间的相关性较高,为0.88(0.84–0.90)。
富集分析
在对中国嘉道理生物样本库(CKB)中通过Bonferroni校正阈值的55种顶级BMI相关蛋白质的富集分析中,有强有力的证据表明,这些蛋白质在多种生物学过程中存在基因本体(GO)富集,包括与动脉粥样硬化相关的过程(如巨噬细胞衍生泡沫细胞分化、脂质代谢)、炎症(IL-6产生)、免疫功能(如T细胞活化、单核细胞增殖、免疫效应过程)以及其他生物学过程(如细胞间黏附、外分泌系统发育、细胞因子介导的信号通路;图4a)。
图4 富集的a基因本体论(GO)生物学过程术语和b京都基因与基因组百科全书(KEGG)通路的弦图,这些是通过GO-BP和b KEGG富集分析得出的、受BMI因果影响的蛋白质(肥胖到蛋白质方向)。右半圆代表前10个GO术语(a)和8个KEGG通路(b)的名称,左半圆是与任何GO术语或KEGG通路显著相关的蛋白质。富集分析针对55种通过遗传分析中Bonferroni校正阈值的蛋白质进行,蛋白质按OLINK面板排序,括号中的数字代表参与GO术语或通路的蛋白质数量。
补充表8提供了除前10个术语外,所有与BMI相关蛋白质显著富集的生物学过程术语的详细信息。 在将所有1463种OLINK蛋白质与所有带注释的蛋白质进行比较的敏感性分析中,共识别出547个显著术语(FDR<0.05),但它们的相对重要性与主要分析中的有所不同(补充表9)。
在使用KEGG方法的类似分析中(图4b和补充表10),共注释出8条通路,包括与肿瘤进展相关的通路(如ECM-受体相互作用、Rap1信号通路)、免疫功能相关的通路(如病毒蛋白与细胞因子及细胞因子受体的相互作用)以及细胞增殖、迁移和黏附相关的通路(如细胞黏附分子)。
双向孟德尔随机化分析
具体来说,当使用两样本孟德尔随机化(2SMR)分析蛋白质与 BMI 的关系时,其中一组样本数据是 BMI 的 GWAS 汇总统计结果(如来自 GIANT 数据库或 Biobank Japan),这些数据记录了不同遗传变异与 BMI 之间的关联强度(如 Beta 值、P 值等),属于 BMI 的遗传关联数据,用于作为结局变量的遗传层面证据。这种数据形式是遗传流行病学研究中分析表型因果关系的常见方式,与 BMI 本身作为生理指标的属性并不冲突。
不同遗传变异与BMI之间的关联强度通过Beta值和P值等指标体现:Beta值表示遗传变异对BMI的效应大小,正值说明该变异与BMI升高相关,负值则相反,绝对值越大,效应越强;P值用于判断关联的统计学显著性,P值越小,表明遗传变异与BMI的关联越不可能是随机误差导致。
这里的遗传变异包含但不限于QTL(数量性状位点),QTL是影响数量性状(如BMI)的基因座,而遗传变异还包括单个核苷酸多态性(SNP)等具体的DNA序列变化,QTL可能由多个这类变异共同构成。
BBJ(Biobank Japan)等大型生物样本库会收集大量人群的基因组数据和表型信息(包括BMI),通过全基因组关联研究(GWAS)分析遗传变异与BMI的关联,进而产生并存储这些关联强度数据,为后续研究提供基础。 在文章的MR(孟德尔随机化)分析中,通常不需要自己重新计算这些关联强度数据。因为GWAS汇总统计数据(如BBJ、GIANT等数据库提供的数据)已经包含了不同遗传变异与结局(如BMI)的关联信息,MR分析可直接利用这些公开的汇总数据,结合暴露(如蛋白质)的遗传关联数据进行分析,从而推断因果关系,这样能提高研究效率,同时利用更大样本量的数据增强结果的可靠性。
结局变量(如 BMI)的遗传关联数据来自 GIANT、Biobank Japan 等数据库的 GWAS 汇总结果,这些结果的背后是无数个体的 BMI 具体数据经过分析处理后的产物。
在中国嘉道理生物样本库(CKB)中,通过全基因组关联研究(GWAS)在1463种蛋白质中识别出742种蛋白质的顺式蛋白质数量性状位点(cis-pQTL),这些位点被用于进一步的双向两样本孟德尔随机化(MR)分析(图1b)。
在CKB与日本生物样本库(BBJ)的两样本MR分析中,经过多重检验校正后,发现8种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15和PRDX6)与体重指数(BMI)存在显著关联(即呈蛋白质到BMI的方向),其中NUDT5还呈现出双向关联(表2)。
此外,利用英国生物样本库(UKB)GWAS中识别出的与这些相同蛋白质相关的384个顺式蛋白质数量性状位点(cis-pQTL)以及遗传调查人体测量性状(GIANT)数据库进行的独立两样本MR分析,复制了3种蛋白质(ITIH3、OGN和TXNDC15)的关联。其中1种蛋白质(ITIH3)在使用不含UKB数据的早期GIANT数据集进行的两样本MR分析中也得到了复制。 在使用MR Steiger检验的敏感性分析中,没有证据表明这8种蛋白质存在反向因果关系,也没有证据显示它们之间存在任何显著的相互作用。在共定位分析中,没有强有力的证据(后验概率H4<0.8)表明这8种蛋白质与BMI存在共同的因果遗传变异。
在使用 MR Steiger 检验的敏感性分析中,未发现这 8 种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15、PRDX6)存在反向因果关系的证据,即可以排除是 BMI 影响这些蛋白质水平,而非这些蛋白质影响 BMI 的情况。这一结果支持了 “蛋白质到 BMI” 方向因果关联的可靠性,强化了这 8 种蛋白质可能在肥胖发生发展中发挥主动作用的结论。
在共定位分析中,针对那8种与BMI存在蛋白质到BMI方向显著关联的蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15、PRDX6),未发现有强有力的证据(后验概率H4<0.8)表明它们与BMI存在共同的因果遗传变异。这意味着,从遗传层面来看,这些蛋白质与BMI的关联可能并非由相同的遗传变异所驱动,进一步支持了它们之间因果关系的独立性,即蛋白质对BMI的影响是通过自身特定的遗传机制实现,而非与BMI共享遗传基础。
表2
以下是对引用内容中相关术语和说明的整理:
- 术语缩写解释:2SMR指两样本孟德尔随机化(two sample Mendelian randomization);EA指效应等位基因(effect allele);EAF指效应等位基因频率(effect allele frequency);KO指敲除(knockout)。
- a EA说明:指在中国嘉道理生物样本库(CKB)中与蛋白质水平升高相关的等位基因,其效应等位基因频率(EAF)数据来自日本生物样本库(Biobank Japan)。
- b 2SMR说明:顺式蛋白质数量性状位点(cis-pQTL)来自CKB,在日本生物样本库中查询全基因组关联研究(GWAS)汇总统计数据。
- c 说明:Beta值和标准误(SE)通过 Wald 比法计算得出。
- d说明:指CKB中蛋白质到BMI方向的观察性结果。
- e2SMR说明:顺式蛋白质数量性状位点(cis-pQTL)来自英国生物样本库(UKB),在遗传调查人体测量性状(GIANT)数据库中查询全基因组关联研究(GWAS)汇总统计数据。
- f说明:加粗的性状或疾病表示P值<5×10⁻⁸,其他为P值<5×10⁻⁶。
- g说明:表达水平通过基因型组织表达(GTEx)数据库估算,并分为三组:+(低)、++(中)、+++(高)。
- h说明:在蛋白质到BMI和BMI到蛋白质两个方向均显著。
在对这8种蛋白质的表型扫描(PheWAS)分析中,基于PhenoScanner的数据,6种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN和EFEMP1)的顺式蛋白质数量性状位点(cis-pQTLs)与多种肥胖相关性状存在关联,包括体重指数(BMI)、腰围(WC)和身体成分。TXNDC15的顺式蛋白质数量性状位点与身高相关,而PRDX6的顺式蛋白质数量性状位点此前未发现与任何性状及疾病结局存在关联。 (6+1+1)
在该研究中,表型全关联分析(PheWAS)使用了 PhenoScanner 和 GWAS Catalog 数据库
使用英国生物样本库(UKB)中这8种蛋白质的不同主要顺式蛋白质数量性状位点进行的表型扫描分析得出了相似结果(补充表11)。此外,这8种蛋白质与已确定的与食欲或饱腹感调节相关的蛋白质(包括AGRP、GHRL、NPY和PYY)相关性不强(相关系数r<0.24)(补充图10)。
在涉及全基因组关联研究(GWAS)目录的表型扫描分析中,未发现与这8种蛋白质相关的其他肥胖相关性状。
在英国生物样本库(UKB)中,“different leading cis-pQTLs”指的是针对这8种蛋白质,在UKB的全基因组关联研究(GWAS)中识别出的、与每种蛋白质相关的不同主要顺式蛋白质数量性状位点(cis-pQTLs)。这些“主要”的cis-pQTLs通常是与对应蛋白质水平关联最强的遗传变异,而“不同”则强调了在UKB人群中使用的这些遗传标记可能与在中国嘉道理生物样本库(CKB)中识别出的cis-pQTLs存在差异,可能因人群遗传背景等因素导致。 研究中使用这些不同的主要cis-pQTLs在UKB中进行表型扫描(PheWAS)分析,发现结果与之前的分析相似,进一步支持了这8种蛋白质与肥胖相关性状或其他表型关联的可靠性。
在相关研究中,主要顺式蛋白质数量性状位点(cis-pQTLs)常被作为蛋白质的遗传标志物,这与它们的特性及研究需求密切相关,具体原因如下: - cis-pQTLs作为蛋白质标志的核心原因:cis-pQTLs是位于蛋白质编码基因附近(通常在1Mb范围内)、与该蛋白质水平显著相关的遗传变异。它们通过影响基因表达或蛋白质合成过程,直接关联蛋白质的循环水平,因此能稳定地反映蛋白质的遗传调控特征,可作为标记物来代表蛋白质的遗传驱动水平。 - 为何不用蛋白质的基因本身:基因序列本身是静态的,而基因表达受多种因素(如环境、表观调控)影响,蛋白质水平更是动态变化且易受个体生理状态干扰。相比之下,cis-pQTLs作为遗传标记具有稳定性(终身不变),且能通过孟德尔随机化等方法排除反向因果和混杂因素,更适合用于推断蛋白质与疾病(如BMI)的因果关系,而直接使用基因难以实现这种因果推断的可靠性。 这种选择使得cis-pQTLs在探究蛋白质与复杂性状的关联中成为更理想的工具,尤其在孟德尔随机化分析中,能有效锚定遗传层面的蛋白质水平,增强研究结论的稳健性。
表型全关联分析(PheWAS)是一种通过检测遗传变异与多种表型(包括疾病、生理性状等)之间关联的研究方法。且在涉及GWAS Catalog的PheWAS分析中,未发现这8种蛋白质与其他肥胖相关性状存在关联。
GWAS Catalog 是一个存储基因组范围关联研究(GWAS)结果的数据库,收集、整理和提供了各种研究中发现的基因 - 表型关联数据。研究人员通过查询 GWAS Catalog,试图找到这 8 种蛋白质与更多肥胖相关性状之间的联系。然而,经过分析,并没有发现这 8 种蛋白质与额外的肥胖相关性状存在关联。这意味着,就目前 GWAS Catalog 所收录的数据以及此次的分析方法而言,这 8 种蛋白质和除了之前已知的那些肥胖相关性状之外,不存在其他方面的关联 。
在组织特异性表达分析中,3种蛋白质(OGN、EFEMP1、PRDX6)在脂肪组织中高表达,1种蛋白质(ITIH3)主要在肝脏中表达,而其余4种蛋白质(LRP11、SCAMP3、NUDT5、TXNDC15)在多种组织中中度表达(补充图11)。
对DrugBank、OpenTargets等数据库的进一步检索未发现这8种蛋白质有任何药物靶点或药物研发相关的证据。
图1
PheWAS:cis-pQTLs for 7 proteins were associated with adiposity traits
在表型全关联分析(PheWAS)中,7 种蛋白质的顺式蛋白质数量性状位点(cis-pQTLs)与肥胖相关性状存在关联。其中,6 种蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1)的 cis-pQTLs 与体重指数(BMI)、腰围(WC)和身体成分等多种肥胖相关性状相关,另一种蛋白质(TXNDC15)的 cis-pQTLs 则与身高相关。
MR Steiger filtering:no evidence of reverse causality for these eight proteins。使用 MR Steiger 过滤法进行了敏感性分析。结果显示,没有证据表明这 8 种蛋白质存在反向因果关系,即排除了是 BMI 水平影响这些蛋白质水平,而非这些蛋白质影响 BMI 水平的可能性,进一步支持了这 8 种蛋白质对 BMI 存在因果效应的结论
Colocalisation analyses:no evidence of their shared causal variants with BMI结果显示,没有强有力的证据(后验概率 H4<0.8)表明这些蛋白质与 BMI 存在共享的因果遗传变异,即这些蛋白质影响 BMI 水平的遗传机制与 BMI 自身相关的遗传变异并非同一套,进一步支持了这些蛋白质对 BMI 的独立因果效应
GTEX:3 proteins highly expressed in adipose tissues在该研究中,利用基因型 - 组织表达(GTEx)数据库对 8 种显著影响 BMI 的蛋白质进行组织特异性表达分析,发现其中 3 种蛋白质(OGN、EFEMP1、PRDX6)在脂肪组织中高表达,这为它们在肥胖相关机制中的作用提供了组织特异性的表达证据。
Protein-Protein interaction:no evidence of any significant interactions通过 STRING 数据库对这 8 种蛋白质进行蛋白质 - 蛋白质相互作用分析,未发现它们之间存在显著的相互作用,表明这些蛋白质可能通过独立的途径影响 BMI 水平
KO mouse:1 protein showing phenotypes related to adiposity在该研究中,对8种经双向两样本孟德尔随机化分析发现显著影响BMI水平的蛋白质(ITIH3、LRP11、SCAMP3、NUDT5、OGN、EFEMP1、TXNDC15、PRDX6)进行了敲除(KO)小鼠相关研究的探索。结果显示,其中1种蛋白质在敲除小鼠中表现出与肥胖相关的表型,为该蛋白质在肥胖相关机制中的作用提供了动物实验层面的支持。
Drug target database:no known drug targets development related to adiposity
讨论
本研究系统地探讨了中国成年人中肥胖与大量蛋白质之间的关联。尽管研究人群相对偏瘦,但在约1500种被研究的蛋白质中,肥胖与超过1000种蛋白质存在显著关联。
此外,遗传分析为体重指数(BMI)对300多种蛋白质的因果关系及明显的线性效应提供了支持,特别是瘦素、FABP4、GOLM2、PON3和NCAN,在男性中,重叠蛋白质的显著关联虽略少,但效应量大于女性。这些观察性和遗传性研究结果在具有不同BMI平均水平的欧洲人群中得到了很大程度的复制。
对选定蛋白质的富集分析表明,肥胖影响多种蛋白质,这些蛋白质参与与动脉粥样硬化、脂质代谢、肿瘤进展、炎症和免疫功能相关的通路。利用中国嘉道理生物样本库(CKB)全基因组关联研究(GWAS)中识别出的顺式蛋白质数量性状位点(cis-pQTLs)进行的孟德尔随机化(MR)分析发现,8种蛋白质显著影响BMI水平,其中1种蛋白质还表现出双向因果关系。
近几十年来,已有多项研究探究了肥胖与血浆蛋白质水平之间的关联,这些研究通过不同平台测量的蛋白质数量各不相同[12–17]。
-
Pang Y, et al. (2021). JAMA Cardiol. 6:276–86.
- 主题:肥胖、循环蛋白生物标志物与主要血管疾病风险的关联。
- 核心内容:研究探讨了肥胖(如体脂参数)与循环中特定蛋白质标志物的关系,并分析这些标志物在血管疾病(如冠心病、中风)发病风险中的作用,可能揭示了肥胖通过蛋白质介导影响血管健康的潜在机制。
-
Bao X, et al. (2022). J Clin Endocrinol Metab. 107:e2982–90.
- 主题:体重指数(BMI)和腰臀比(WHR)的蛋白质组学特征及其在糖尿病发病中的作用。
- 核心内容:通过蛋白质组学分析,识别与 BMI 和 WHR 相关的血浆蛋白,探讨这些蛋白如何介导肥胖与 2 型糖尿病的关联,为糖尿病的早期预测和干预提供潜在的蛋白标志物。
-
Ponce-de-Leon M, et al. (2022). Transl Res. 242:93–104.
- 主题:炎症相关蛋白与肥胖的新型关联 —— 基于四项人群研究的靶向蛋白质组学分析。
- 核心内容:在多个人群队列中,通过靶向检测炎症相关蛋白,发现了与肥胖相关的新型炎症蛋白,强调了炎症通路在肥胖发生发展中的作用,为肥胖的炎症机制提供了新证据。
-
Goudswaard LJ, et al. (2021). Int J Obes (Lond). 45:2221–9.
- 主题:肥胖对人类血浆蛋白质组的影响:观察性研究与孟德尔随机化分析。
- 核心内容:结合观察性数据和孟德尔随机化(MR)方法,评估肥胖(遗传预测的)对血浆蛋白质组的因果效应,识别出肥胖可能直接调控的蛋白质,为肥胖相关疾病的潜在靶点提供线索。
-
Sun BB, et al. (2022). bioRxiv. 2022-06
- 主题:54,306 名英国生物银行参与者中人类血浆蛋白质组的遗传调控。
- 核心内容:基于大规模人群样本,分析血浆蛋白质水平的遗传调控机制(如遗传变异对蛋白表达的影响),鉴定出大量蛋白质的遗传位点,为理解蛋白质的遗传基础及其与疾病的关联提供了重要资源(注:该文献为预印本,尚未正式发表)。
在一项对来自三个不同人群(德国、英国和卡塔尔)的4600名参与者的921种SomaScan蛋白质的联合分析中,在观察性分析和遗传分析中分别有152种和24种蛋白质与BMI显著相关,其中瘦素、IGFBP1和IGFBP2是关联性最强的[17]。 最近的一项英国研究使用SomaScan平台在2737名参与者中测量了3622种蛋白质,结果表明自我报告的BMI(平均值25.9 kg/m²)与1576种(44%)蛋白质显著相关[15]。然而,在遗传分析中,只有8种蛋白质(0.5%,8/1576)与BMI显著相关,包括瘦素、FABP4、PILRA和INHBB,
而在本研究中,应用相同的Bonferroni校正阈值时,这一比例为6.9%(55/798)。 结果存在差异的原因可能在于所使用的检测平台、纳入的蛋白质类型、BMI测量的可靠性(自我报告与中国嘉道理生物样本库(CKB)中的测量值)不同,或者所使用的遗传工具的统计效力存在差异(BMI方差解释率:2.8% vs CKB中的3.7%)。尽管如此,在相对偏瘦的中国成年人中进行的本项遗传分析,证实了该研究中四个蛋白质关联(瘦素、FABP4、PILRA)中的三个,这些蛋白质也包含在本研究的OLINK检测平台中。
最近,研究人员使用相同的OLINK平台对英国生物样本库(UKB)中约5万名参与者的1463种蛋白质进行了定量分析[16]。在对UKB数据进行的单独分析中,采用了类似的协变量调整方法,结果发现在观察性分析和遗传分析中,分别有1379种和935种蛋白质与体重指数(BMI)显著相关,这复制了在中国嘉道理生物样本库(CKB)中发现的90%以上的BMI相关蛋白质。此外,尽管这两个人群的BMI分布范围不同(UKB的平均BMI为27.4 kg/m²,CKB的平均BMI为23.9 kg/m²),但在传统分析和遗传分析中,重叠蛋白质的效应量之间存在高度相关性。对于研究结果不一致的蛋白质,其可能的原因尚只能推测,这可能包括研究效力、特定蛋白质遗传结构的差异以及存在种族特异性机制的可能性。因此,本研究涉及中国和英国人群,为BMI与大量蛋白质的血浆水平在广泛的BMI分布范围内存在因果关联提供了强有力的新证据,这进一步凸显了主要研究结果的普适性和全球相关性。
对中国嘉道理生物样本库(CKB)中排名前55位的蛋白质进行富集分析后发现,这些差异表达的蛋白质与多种生物学过程相关,包括巨噬细胞相关的泡沫细胞分化、IL-6产生和免疫细胞功能。事实上,巨噬细胞在动脉粥样硬化斑块的形成中起着关键作用[32]。此外,与脂质代谢相关的代谢过程也被富集,这与心脏代谢疾病的发生和发展相关。另外,IL-6的产生也被富集,突出了促炎状态的作用。炎症与多种疾病有关[33],而肥胖可能通过增强炎症状态影响免疫系统[34]。肥胖还会损害免疫功能和白细胞计数,并且会加强脂肪组织局部炎症与免疫反应改变之间的正反馈循环,这两者都有助于心脏代谢疾病的发生和后遗症[34]。 在使用KEGG方法的分析中,几种受肥胖影响的蛋白质(如CSF1、PGF)与细胞外基质(ECM)-受体相互作用和Rap1信号通路相关。值得注意的是,Rap1是肿瘤进展中的关键因素,靶向Rap1信号及其调节因子可能潜在地控制癌变、转移、化疗耐药和免疫逃逸[35]。ECM-受体相互作用信号通路也被发现可能与乳腺癌的发展有关[36]。 总之,这些在相对偏瘦的中国成年人中的富集分析结果,揭示了肥胖可能增加疾病风险的多种复杂通路。
本研究的主要优势包括:对大量蛋白质进行了评估;在不同 ancestry人群中独立重复验证了主要结果;使用了可靠的跨 ancestry 肥胖遗传工具;应用了双向孟德尔随机化(MR)方法;此外,还通过富集分析阐明了多种生物学过程。而且,本研究纳入的肥胖平均水平和范围与西方人群存在显著差异。 然而,本研究也存在局限性:首先,研究未考虑其他几种肥胖相关性状(如腰围、腰臀比、体脂率),也未充分研究与肥胖呈二次关联的蛋白质;其次,无法明确遗传分析中男女之间的明显差异是由与性别相关的生物学机制导致,还是仅仅因统计效力有限造成的假象;第三,由于公开可得的全基因组关联研究(GWAS)汇总统计数据中缺乏重叠的顺式蛋白质数量性状位点(cis-pQTLs),双向两样本孟德尔随机化分析仅涉及极少数蛋白质[42,43],因此无法证实(或反驳)先前关于某些蛋白质(如LEP、AGER、DPT和CTSA)可能影响体重指数(BMI)的研究发现[17];第四,对于使用公开可得的汇总遗传数据进行的主要双向孟德尔随机化分析,无法完全解决因样本重叠可能产生的碰撞偏倚,尽管研究人员在统计效力大幅降低的较小数据集上进行了敏感性分析以尽量减少此类偏倚。 未来的研究需要更大的样本量和更好的遗传工具(可能包括顺式和反式蛋白质数量性状位点),以在不同人群中进一步重复和阐明不同蛋白质对体重指数和其他肥胖相关性状的影响(或反之),包括蛋白质间相互作用以及存在共享因果遗传变异的证据。
在该研究中,“与肥胖呈二次关联”指的是部分蛋白质与肥胖(以BMI为指标)之间的关联并非简单的线性关系,而是呈现出二次函数形式的非线性关联,即随着BMI的变化,蛋白质水平的变化速率会发生改变(例如先升后降或先降后升)。 研究提到,在1156种与BMI无显著线性遗传关联的蛋白质中,有9.9%(91种)显示出与BMI存在二次关联的证据,但这些关联在多重检验校正后均未达到统计学显著性()。这种二次关联提示,某些蛋白质与肥胖的关系可能随肥胖程度的不同而发生方向性或强度的改变,但其生物学意义仍需进一步验证。
在该研究中,双向两样本孟德尔随机化(MR)分析需以顺式蛋白质数量性状位点(cis-pQTLs)作为遗传工具变量,而cis-pQTLs需同时存在于暴露(蛋白质)和结局(BMI)的全基因组关联研究(GWAS)数据中,才能实现双向因果关系的检验。 但由于公开可得的GWAS汇总统计数据中,不同研究(如中国嘉道理生物样本库(CKB)与日本生物样本库(BBJ)、英国生物样本库(UKB)与遗传调查人体测量性状(GIANT)数据库)所包含的cis-pQTLs存在差异,能够同时用于蛋白质和BMI关联分析的重叠cis-pQTLs数量较少。 这种数据局限性导致双向两样本MR分析仅能针对极少数拥有重叠cis-pQTLs的蛋白质进行,无法全面探究更多蛋白质与BMI之间的双向因果关系,这也是研究中提到的一项局限性。
在该研究中,当使用公开可得的汇总遗传数据进行主要的双向孟德尔随机化(MR)分析时,由于不同研究数据可能存在样本重叠(即部分个体数据可能同时被纳入不同的GWAS中),这种重叠可能导致碰撞偏倚——即变量之间的关联并非真实的因果关系,而是由样本重叠这一外部因素所导致。 尽管研究人员通过在统计效力大幅降低的较小数据集上进行敏感性分析,试图尽量减少此类偏倚,但受限于数据本身的特性和分析方法的局限性,无法完全消除这种偏倚对结果的潜在影响,这是该研究存在的一项局限性。
总体而言,这项针对相对偏瘦中国成年人的研究表明,肥胖与大量蛋白质存在显著关联,有证据支持300多种蛋白质在体重指数(BMI)对蛋白质的方向上具有因果相关性。双向孟德尔随机化(MR)分析还发现,8种蛋白质可能会影响肥胖水平,这可能为未来的药物研发提供参考。结合富集分析和现有的实验数据,本研究确定了肥胖可能增加疾病风险的多种通路,并为肥胖及肥胖相关疾病的潜在治疗提供了新的蛋白质靶点支持。
问题
遗传关联和MR分析的区别是什么
在该研究中,遗传关联和孟德尔随机化(MR)分析的区别主要体现在以下方面: ### 1. 定义与核心目的 - 遗传关联:主要通过遗传工具(如BMI遗传评分)探究遗传预测的BMI与蛋白质水平之间的关联,旨在识别受遗传因素影响的BMI与蛋白质之间的统计学关联,其核心是基于遗传变异对BMI的预测作用,观察这种遗传预测的BMI与蛋白质水平的关系🔶1-67🔶。 - MR分析:是一种利用遗传变异作为工具变量来推断暴露因素(如蛋白质水平)与结局(如BMI)之间因果关系的方法,在本研究中,双向MR分析用于明确蛋白质与BMI之间的因果方向,即判断是蛋白质影响BMI,还是BMI影响蛋白质,或存在双向影响🔶1-91🔶。 ### 2. 分析对象与方向 - 遗传关联:聚焦于遗传预测的BMI对蛋白质水平的影响,方向主要是“BMI(遗传预测)到蛋白质”,分析遗传衍生的BMI与1463种蛋白质之间的关联情况,识别出显著相关的蛋白质🔶1-67🔶。 - MR分析:不仅关注“BMI到蛋白质”的方向,更重要的是探究“蛋白质到BMI”的方向,通过cis-pQTLs作为工具变量,判断蛋白质是否对BMI有因果影响,还会进行双向分析以确定是否存在双向因果关系(如NUDT5同时存在双向关联)🔶1-91🔶。 ### 3. 结果呈现与意义 - 遗传关联:在FDR<0.05时,发现307种蛋白质与遗传衍生的BMI显著相关,这些关联更多地提示遗传预测的BMI可能对蛋白质水平产生影响,为理解BMI与蛋白质之间的潜在因果联系提供基础,且91%的遗传关联蛋白质在观察性分析中也存在关联🔶1-68🔶。 - MR分析:最终确定8种蛋白质(如ITIH3、OGN等)显著影响BMI水平,其中部分在不同人群中得到复制,这些结果为识别肥胖及相关疾病的潜在治疗靶点提供了更直接的因果证据,强调了蛋白质对BMI的主动影响作用🔶1-91🔶。